VGG2Vec: Extracting Image Representations from Neural Networks
In this post I will introduce VGG2Vec, a method to create a vector representation of images using neural networks. By extracting the vector representation of an image from a trained neural network, you can take advantage of what the neural network has learned about the picture. We’ll visualize our representations to show that they encode information about different artists’ styles as well as subject matter.
Neural Networks in 30 seconds
First, a quick primer on what neural networks are and how they work. Each layer of a neural network transforms its input data, warping the space it occupies. With multiple layers stacked atop each other, neural networks perform successive transformations to bring out relevant features. The final output is then used to represent the original input when it’s fed into a (usually) logistic-regression classifier.
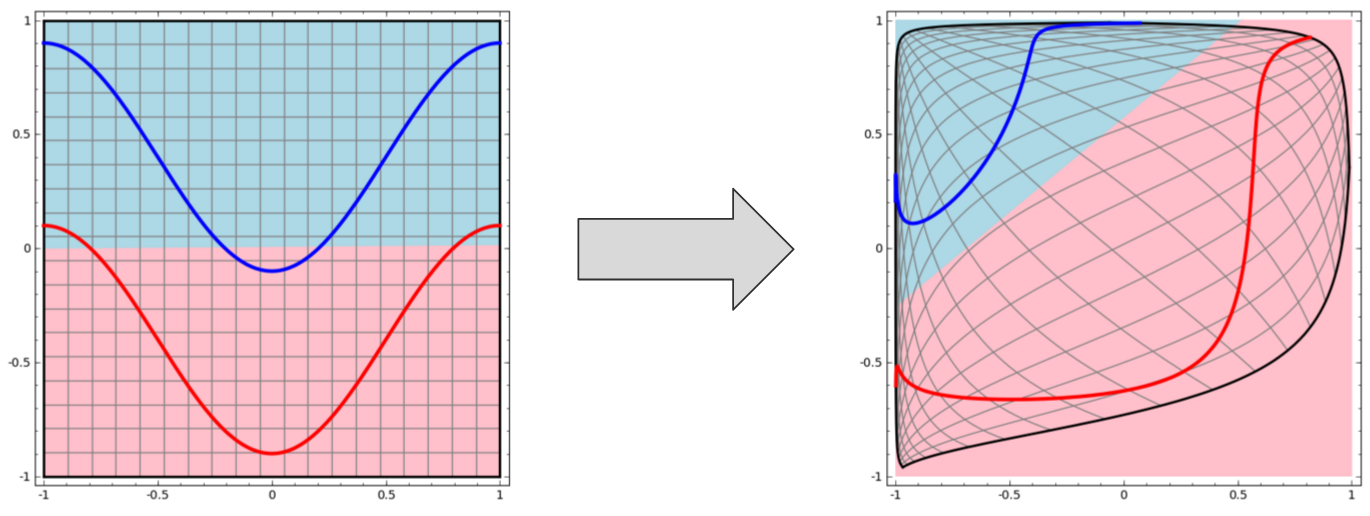 Each layer of a neural network creates a new representation of the input
Each layer of a neural network creates a new representation of the input
You don’t really need to worry about most of the details of how neural networks work (if you want to know more, read Chris Olah’s superb explanations)1.
Hierarchical representations
One of the neat things about deep networks is that because each layer takes its input from the previous layer, earlier layers highlight low-level features like lines and edges while later layers recognize composite features like shapes and objects.
 Feature detection at different layers of a neural network (source Erhan et al. 2009)
Feature detection at different layers of a neural network (source Erhan et al. 2009)
The images above are illustrations of the features detected by each individual neuron in the first, second, and third layers of a neural network trained to recognize handwritten digits (MNIST). You can see that the features that the first layer is “looking for” tend to be simple patterns like curves and lines while the third layer activates on more complex patterns output by the previous layers.
The power of vector representations
Vector representations have been the target of tremendous interest over the past few years. If we can represent the data that interests us – text, images, audio – as a simple series of numbers (a vector), then they become much easier for computers to work with. Vector space is the range of values a vector can have; vectors with similar values are closer together in vector space.
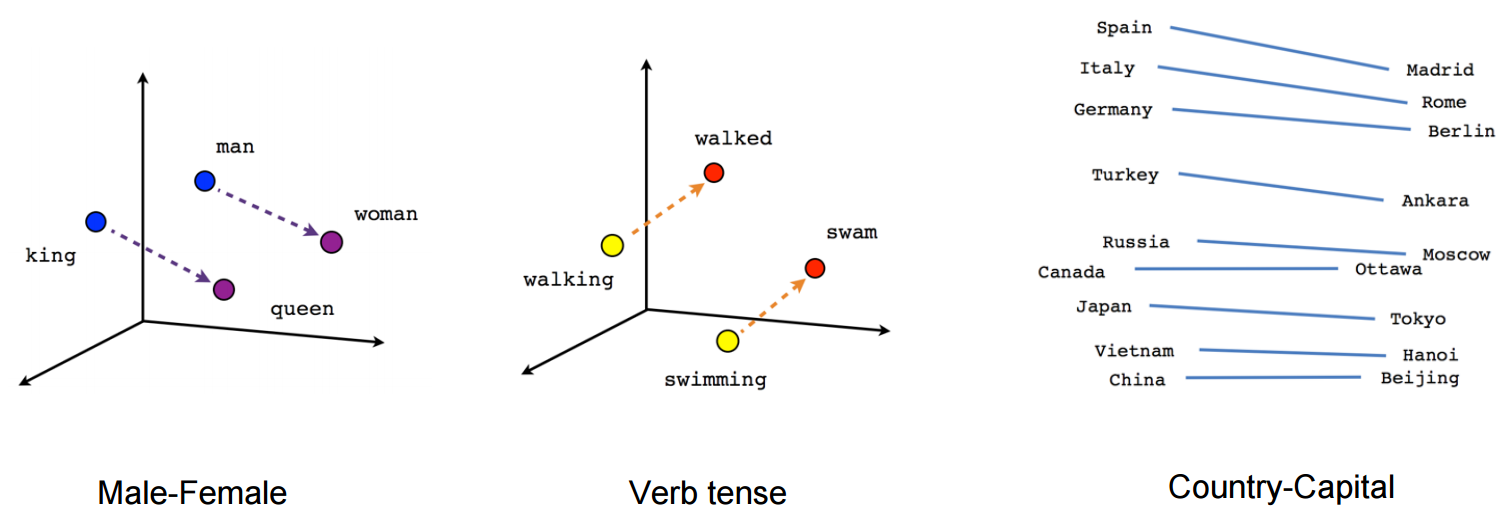 Vectors allow us to quantify and visualize semantic relationships (source: Tensorflow docs)
Vectors allow us to quantify and visualize semantic relationships (source: Tensorflow docs)
Word2Vec is a tool that Google released to construct vector representations of words based on their usage; words that have similar usages are mapped to nearby locations in vector space. Researchers quickly found that these vectors encoded all kinds of relationships, allowing for a mathematical understanding of the semantic space understood by the model. These vectors encode grammatical relationships like gender and tense but also encode more abstract relationships between words.
VGG2Vec
VGG2Vec uses the VGG-19 neural network (which has performed well on a variety of transfer-learning tasks) to construct a hierarchical representation of an input image. Specifically, by extracting the transformed input at selected layers, we can grab the features selected by the neural network without performing classification.
What this gives us is a set of features from each layer of the neural network, encoding all of the patterns that the neural network has learned. In particular, we take the feature output from layers relu1_2, relu2_2, relu3_4, relu4_4, and relu5_4. In order to abstract the contents of the vectors from their spatial position, we use the Gram matrix2 of these vectors. This produces a vector in N = 610,304 dimensions (642 + 1282 + 2562 + 5122 + 5122). Yes, that’s big.
Visualizing Picasso with VGG2Vec
Here we’ll use VGG2Vec to create vectors representing Picasso paintings from across his many distinct eras. In order to visualize these high-dimensional vectors, I use t-SNE, a common dimensionality reduction algorithm which allows us to view relative distance in two dimensions.
As you can see below, the vectors group on content as well as style – themes that Picasso revisited in different styles are clustered together, demonstrating changes and refinements to specific ideas. Click the picture to explore the visualization yourself!
 A visualization of Picasso paintings as represented by VGG2Vec. Click to explore the interactive version.
A visualization of Picasso paintings as represented by VGG2Vec. Click to explore the interactive version.
Comparing painters with VGG2Vec
We can also use VGG2Vec to explore similarities and differences between different artists, as understood by VGG-19. For the visualization presented below, I took ten paintings from nine distinctive artists: Jackson Pollock, Vincent Van Gogh, Gustav Klimt, Salvador Dalí, Pablo Picasso, Paul Cezanne, Leonardo Da Vinci, Claude Monet, and Georgia O’Keeffe. I then used VGG2Vec to make vector representations of each of these paintings and visualized the vectors using t-SNE:
 A visualization of the various painters as represented by VGG2Vec. Click to explore the interactive version.
A visualization of the various painters as represented by VGG2Vec. Click to explore the interactive version.
What does this mean?
With VGG2Vec anyone can access the wealth of information encoded by a neural network without needing to understand deep learning. By modelling relationships between image representations, researchers and art historians alike can take advantage of this new technology to look at images in a new light.
You can see how I made the visualizations above on GitHub in an iTorch notebook. The code is a little dirty but I’ll be cleaning it up in the coming days.
Thanks for reading!
Notes:
-
Chris Olah’s blog is phenomenal. His clear explanations were how I first started learning about neural networks and as I’ve continued to revisit his materials they continue to enlighten me in new ways. Click the link ↩
-
A Gram matrix is a spatial summary statistic defined as all possible inner products of a vector, of the inner product of a vector and its transpose. ↩